Blog Tecnológico
Power BI - Desempenho do relatório
Erick Reis • 23 fev 2023 • Microsoft Power BI

Muitas vezes quando estamos lidando com modelos de tabelas relacionais, nos deparamos com algumas situações que podem nos trazer vantagens e desvantagens. Pois dependendo da forma com que os dados estão distribuídos entre as tabelas, esses dados trafegam de diferentes formas.
Hoje utilizarei o Power BI, mas ele segue para diversos tipos de ferramentas que lidam com tabelas relacionais.
O modelo que tende a trazer um melhor desempenho para o nosso modelo de dados, é aquele onde temos informações distribuídas entre tabelas Fato e Tabela Dimensão.
Recapitulando o que vimos em artigos anteriores, a Tabela Fato é aquela tabela que:
- Sempre registra informações de fatos que acontecem no seu dia a dia
- Cada linha geralmente apresenta uma história/Fato diferente
- Os dados são altamente redundantes
- Tende a ser a maior tabela do nosso conjunto de informações
Já a tabela dimensão possui um objetivo diferente da tabela Fato:
- Ela vem com o intuito de auxiliar, explicar ou complementar os dados da tabela Fato
- Os dados chave não podem se repetir
- Se parece muito com uma tabela de Cadastro
Quando aplicamos esse modelo para as nossas tabelas, existem duas formas de trabalharmos com essas tabelas que são as seguintes:
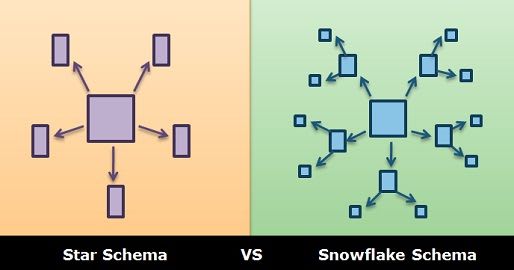
Modelo Estrela
A modelo estrela é o melhor e o ideal a ser utilizado sempre que trabalhamos com modelos de dados relacionais, isso porque ele garante uma rápida e única conexão das tabelas dimensão com a tabela fato.
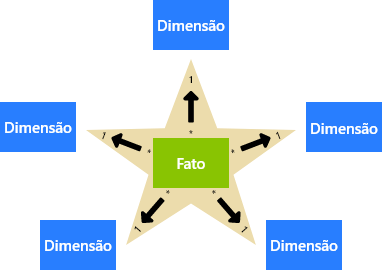
A modelo estrela nos permite uma conexão e um acesso mais rápido as informações que estão nas tabelas dimensão. Isso porque se precisarmos consultar alguma informação na tabela dimensão, o Power BI precisará percorrer apenas um caminho da tabela dimensão para a tabela fato.
Claro que nem sempre conseguimos utilizar esse modelo, mas sempre que possível se pudermos modelar os dados para esse esquema estrela mais fácil será para trabalharmos a informação.
Modelo Floco de neve
Muitas vezes vamos ter casos em que as tabelas não se relacionarão diretamente com a tabela fato. Podem ter casos em que uma tabela dimensão se relaciona com outra tabela dimensão, e para esse tipo de modelo nós damos o nome de Snowflake (Ou floco de neve).
Como comentamos anteriormente, não é um modelo ideal a ser trabalhado pois sua performance é menor em comparação com o modelo estrela. Isso porque no modelo floco de neve, temos uma tabela dimensão que se relaciona com outra, aumentado o caminho que a informação precisa percorrer até chegar na tabela fato.
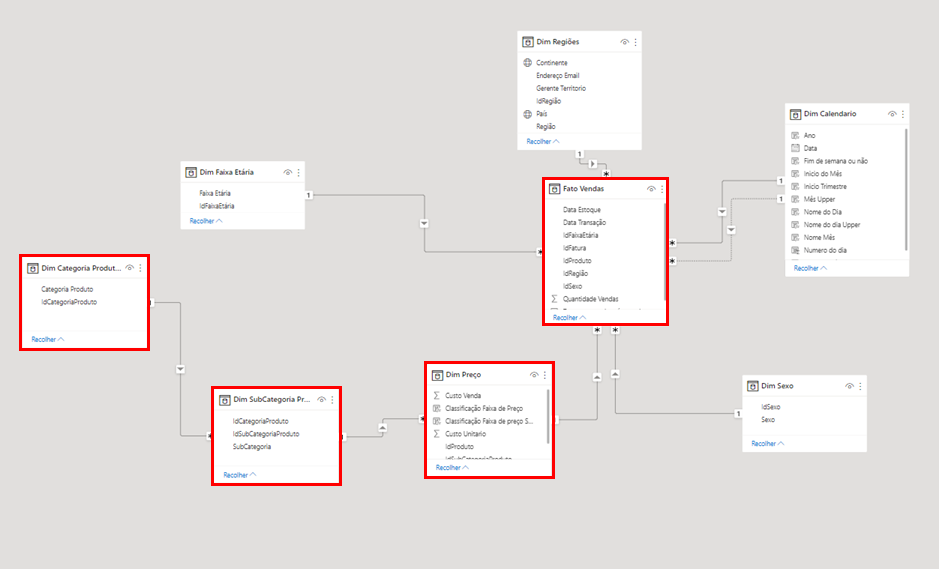
Como no exemplo abaixo, onde temos uma dimensão Categoria do Produto, se relacionando com uma outra tabela dimensão chamada Subcategoria do Produto, que se relaciona com uma tabela dimensão chamada Preço que se relaciona com a tabela fato.
Então notem que o percurso é muito maior do que no modelo estrela:
Representação dos dois modelos:
Mas vamos ver essas diferenças na prática?
Aqui temos uma imagem de um relacionamento feito usando o modelo floco de neve:
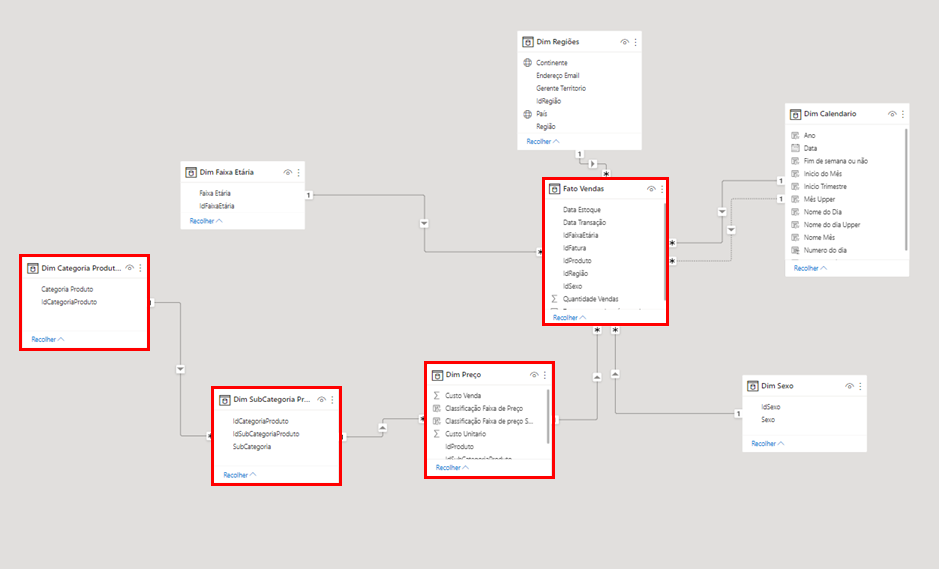
Agora vou criar um visual utilizando como base a tabela de Dim Categoria ( Que é a tabela que não se relaciona direto com a tabela Fato), e vou criar um outro visual usando a Dim Faixa Etária ( Tabela que se relaciona de forma direta com a tabela Fato vendas)
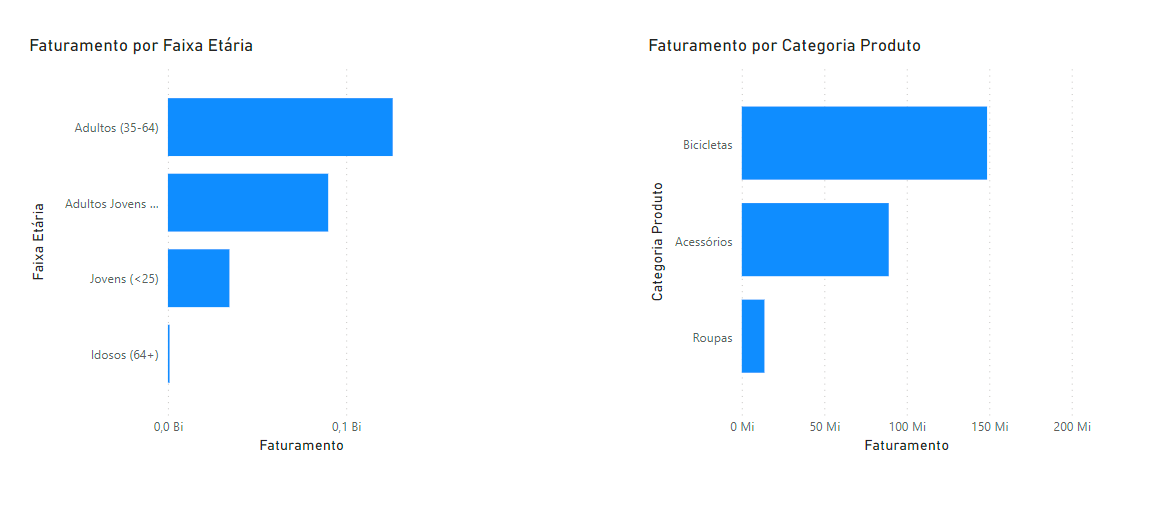
São dois gráficos que ficaram bem parecidos pela quantidade de informações.
Agora vamos ver quanto tempo o Power BI leva para processar esses dados e conseguir gerar esses visuais baseado nos tipos de relacionamento que temos entre as tabelas.
Para isso, irei utilizar o Performance Analyzer que está dentro do próprio Power BI.
Essa ferramenta calcula quanto tempo o Power BI leva para processar os dados e conseguir gerar os visuais.
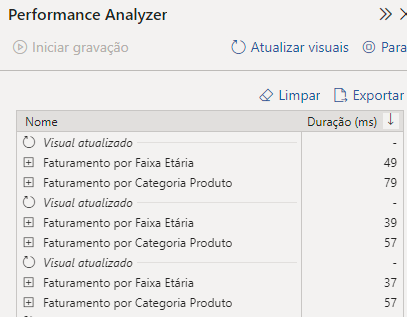
Fiz o teste e refiz mais duas vezes para mostrar para vocês como a forma com que as suas tabelas estão relacionadas, acaba afetando sim o resultado final do seu relatório.
Notem que nos três testes feitos, o visual de Faturamento por Categoria Produto levou mais tempo para ser gerado. Isso porque como vimos anteriormente, a tabela Categoria Produtos não está relacionada diretamente com a tabela Fato. O que faz com que o caminho pela qual a informação percorra seja muito maior do que o caminho feito pela tabela de Faixa etária, que está relacionado de forma direta com a tabela Fato.
Por isso sempre que possível, é interessante trabalharmos com o modelo de dados desenhado no modelo Estrela. Pois dessa forma você garante que a informação vai ser percorrida entre as tabelas de uma forma muito mais rápida.
Gostou deste conteúdo?

Erick Reis
Graduado em Análise e desenvolvimento de sistemas pela FAM, apaixonado por tecnologias que envolvam análise de dados, programação, banco de dados. Atualmente atuando em tecnologias de análise de dados como: Power BI, Excel, Banco de dados. Erick conquistou sua Certificação em Power BI, na ENG DTP & Multimídia. E veio a se tornar um MCT em Power BI, na ENG DTP & Multimídia.
.png "Microsoft Power BI: Dados Brutos em Insights")
.png "Microsoft Power BI: Funções DAX um Guia")
.png "Power BI com SQLServer: DirectQuery ou Import")
.png "Microsoft Power BI: Narrativas Inteligentes Botões Indicadores")

.png "Power BI: Formatação Condicional")